
Customer Care Service: Turning Negative Feedback to Gold
In the realm of customer care service, where every interaction is a chance to dazzle, it's not just about responding; it's about active listening. The secret to turning negative feedback into gold lies in mastering the art of attentive listening. Let's dive into why it matters and how you can turn a simple response into a customer care masterpiece.
Understanding the Power of Active Listening
In the world of customer care, the basic response is the bare minimum – the 'thanks for reaching out, we'll look into it' routine. But, the magic happens when you move beyond the basics. Active listening means tuning into your customer's feelings, understanding the nuances, and showing genuine empathy. It transforms a routine interaction into a memorable experience.
The Dance of Empathy: Connecting on a Human Level
Empathy is your superhero cape in the customer care world. When addressing negative feedback, it's not just about solving the problem; it's about acknowledging the customer's feelings. Picture it like a dance – step into their shoes, feel the rhythm of their frustration, and then gracefully guide them to a solution. It's not just an interaction; it's a connection.
Turning the Tide: Transforming Negativity into Positivity
Negativity often holds untapped potential. By actively listening, you can uncover the root cause of the issue and turn it around. Instead of a mere apology, offer a solution tailored to their concerns. It's not just about pacifying; it's about flipping the script and leaving your customer with a positive experience despite the initial hiccup.
The Gold Mine of Feedback: Learning and Growing
Every complaint is a nugget of gold in the vast mine of customer feedback. Through active listening, you unearth valuable insights into your business's strengths and weaknesses. In brief, embrace negative feedback as a tool for growth. Learn, adapt, and watch your customer care service evolve into a powerhouse that turns challenges into triumphs.
The ABCs of Active Listening
Active listening isn't rocket science; it's about mastering the ABCs – Always Be Considerate. When your customer feels heard and understood, it's a game-changer. Repeat their concerns, validate their feelings, and assure them that you're here to help. It's not just about resolving issues; it's about making your customers feel valued.
The Power of Prompt Responses
In the fast-paced world of customer care service, timing is everything. A prompt response not only showcases your commitment but also prevents minor issues from escalating. Actively listening doesn't mean delaying solutions. Respond swiftly, assure your customer that their concerns matter, and set the stage for a positive resolution.
Personalization: The Heart of Customer Care
Make it personal. Hence, dive into the details of the customer's issue, address them by name, and tailor your response to their unique situation. Personalization elevates your customer care service from generic to exceptional. It's not just about solving problems; it's about showing that each customer is a valued individual, not just a ticket number.
Active Listening in the Digital Age
In the era of emojis and digital expressions, active listening extends beyond words. For example, pay attention to the tone, sentiment, and context of your customer's messages. Embrace the nuances of digital communication, and respond in a way that reflects your commitment to providing a seamless and attentive customer care experience.
How Outsourced Teams Handle Crisis Situations
In the dynamic world of customer care service, crises can pop up like unexpected plot twists in a Netflix series. However, how do outsourced teams handle these curveballs and turn crisis situations into opportunities for customer satisfaction? Buckle up; we're about to spill the beans.
Navigating the Storm: Customer Care Service
When it comes to customer care service, outsourced teams are the unsung heroes during crises. They're the calm in the storm, the problem-solving wizards who thrive under pressure. Your customer doesn't need to know the behind-the-scenes drama; they just want a solution. And outsourced teams? They make it happen.
The Power of Swift Adaptability
Outsourced teams are the chameleons of customer care service. So what if did the crisis hit? They adapt, and fast. From sudden spikes in inquiries to unexpected technical glitches, they roll with the punches. Their secret? Swift adaptability. On the whole, they don't just weather the storm; they dance in the rain.
Proactive Problem-Solving Magic
Ever wished for a customer care genie to fix things before you even realized there was a problem? Outsourced teams are the next best thing. They're not just reactive; they're proactive. Crisis prevention is their forte, and your customers get the magic of seamless service without even knowing there was a hiccup.
Emotional Intelligence in Overdrive
Crises aren't just about fixing technical glitches; they're about handling emotions. Outsourced teams are emotionally intelligent superheroes. That is because they understand the frustration, the anxiety, and the urgency. Consequently, with empathy as their superpower, they turn crisis situations into moments of connection and understanding.
The Art of Transparent Communication
Communication is key during a crisis. Outsourced teams don't sugarcoat or evade, but they communicate transparently. No jargon, no confusing messages. Just clear, honest communication that reassures your customers and keeps them in the loop. As a result: crisis averted, satisfaction intact.
Collaborative Crisis Resolution
Outsourced teams aren't lone wolves; they're team players. When a crisis hits, they collaborate seamlessly with your in-house team. It's not a 'you vs. us' scenario; but more like a unified front against the unexpected. They bring expertise, your team brings insights, and together, crisis resolution becomes a tag-team spectacle.
Post-Crisis Reflection for Continuous Improvement
Crises aren't just incidents to forget. Outsourced teams are the kings of post-crisis reflection. To illustrate, they analyze, dissect, and learn. What went wrong? How can it be avoided in the future? It's not just about fixing the present, but it's about ensuring a better future for your customer care service.
Embracing Reviews: The Good, Bad, and Ugly
Ah, reviews – the unsung heroes of the customer care service world. From glowing testimonials to the occasional stinger, they're your business's mirror. Therefore, let's navigate the realm of reviews together, from the downright fantastic to the 'could use improvement.'
The Good: A Symphony of Praises
Positive reviews are the sweet serenade your customer care service deserves. When your team hits the right notes, customers sing your praises. These are the high-fives, the virtual hugs, the testimonials that make your heart do a happy dance. As a result, bask in the good vibes; you earned it.
Harnessing the Power of Positivity
Positive reviews are more than just feel-good moments. They're potent tools for boosting your brand. So share them on your website, flaunt them on social media and let the world know you're a customer care superstar. In brief, positivity is contagious, and your brand is the carrier.
Cultivating Customer Advocates
Ever dreamed of an army of brand advocates? Positive reviews are just like a secret weapon that, as a result, turn satisfied customers into your greatest cheerleaders. In this situation, encourage them to share their experiences, write testimonials, and spread the word. Customer care service brilliance? It's spreading, and so is loyalty.
The Bad: Turning Lemons into Lemonade
Not every review is sprinkled with stardust. Bad reviews happen, and it's okay. Treat them like sour lemons, and let's make some lemonade. In brief, respond with grace, show empathy, and turn a negative experience into an opportunity for redemption.
Responding with Grace and Empathy
When faced with a less-than-stellar review, respond with grace and empathy. Acknowledge the concern, apologize sincerely, and assure them you're here to make things right. On the whole, it's not just about resolving the issue; it's about turning a critic into a fan.
Learning from Critique for Continuous Improvement
Bad reviews aren't setbacks; they're stepping stones. So embrace them as lessons in disguise. Analyze the feedback, identify patterns, and implement changes. Continuous improvement is the heartbeat of stellar customer care service. Finally, the more you learn, the better you become.
The Ugly: When Criticism Crosses the Line
Sometimes, reviews take an ugly turn – the realm of trolls and unjustified rants. Thus, you have discovered the dark side of the internet. But don't take it to heart; instead, let your response be a beacon of professionalism.
Keeping Your Cool in the Face of Criticism
Ugly reviews can sting, but remember, your response is your armor. Stay calm, address the issue professionally, and rise above the negativity. It's not just about combating criticism; it's about showcasing your unwavering commitment to customer care service excellence.
When to Engage and When to Walk Away
Not every battle is worth fighting. Choose your battles wisely. If a review crosses the line into harassment, it's okay to disengage. Maintain your professionalism, offer a solution if possible, but sometimes, walking away is the best path to preserve your brand's integrity.
Brands that Transformed Through Feedback
Ever wondered how the giants in the business world became, well, giants? The secret often lies in the art of turning negative feedback into gold. Therefore, let's delve into the inspiring stories of brands that transformed through the alchemy of customer feedback.
Netflix – Turning Criticism into Content Brilliance
Netflix, the streaming giant we all love, wasn't always smooth sailing. Previously, subscriber dissatisfaction was brewing over their content library. How did they turn it around? You spoke, and Netflix listened. They revamped their content strategy, producing original shows that became global hits. So, next time you're binging on Stranger Things, remember – your feedback helped build this empire.
Your Voice, Their Script
Your dissatisfaction with the same old shows transformed into a content revolution. On the whole, Netflix harnessed the power of customer care service feedback, turning your critiques into blockbuster scripts. Finally, your voice shaped their storyline.
Starbucks – Brewing Perfection from Bitterness
Even the behemoth coffee empire, Starbucks, faced a bitter brew of criticism. Formerly, customers felt the company was becoming too corporate, losing the cozy coffee shop charm. Starbucks listened, rekindled the flame of connection, and transformed their stores into welcoming, community hubs. Later, your demand for a personalized touch turned Starbucks into your home away from home.
A Latte Love for Your Feedback
Your desire for a more personal touch brewed a transformation. Consequently, Starbucks listened, added comfy chairs, and made their spaces feel like your living room. Thus, your feedback fueled the warmth in your daily cup.
Apple – The Genius of Adapting to Critique
Even the tech titan Apple faced its share of customer care service challenges. Remember the iPhone 4's antenna-gate fiasco? Users complained, and Apple didn't just fix the antennas; they redesigned their entire feedback system. Thus, your critiques became the catalyst for Apple's commitment to quality assurance.
Your Gripes, Their Innovation
Critiques transformed Apple's approach. They revamped their feedback system, ensuring your voice guides their innovations. Hence, your gripes became their roadmap to better products.
In conclusion, these brands didn't just weather the storm of negative feedback; they surfed the waves and emerged stronger. As a result, your critiques aren't just complaints; they're the gems that shape the business landscape. So, the next time you offer feedback on your favorite service or product, remember, you're not just sharing thoughts – you're contributing to the transformative journey of customer care service excellence.

Outsourcing Customer Service In Fintech: Cutting Costs, Not Quality
In the dynamic world of Fintech, keeping expenses lean is a game-changer. But how do you trim the fat without sacrificing quality? Enter the world of outsourcing customer service. It’s like having your cake and eating it too – all while saving a pretty penny. Let’s dive into the economic magic of outsourcing customer service and see how it balances the financial equation in your favor.
Cut Those Overheads
We all know that hiring, training, and retaining an in-house team can drain your resources. It's not just about salaries; think about the additional costs – training, infrastructure, benefits, and the list goes on. By outsourcing customer service, you bid goodbye to these hefty expenses. You only pay for the service, and suddenly, the cost of world-class customer support isn’t giving you sleepless nights anymore. Your balance sheet will breathe a sigh of relief, and so will you.

Pay for What You Need
Why shell out for 24/7 staff when you only need after-hours support? With outsourcing, you tailor the service to your exact needs. Whether it’s full-time, part-time, or occasional support, you get precisely what you require, and you pay just for that. It’s a beautiful, cost-effective solution that aligns with your business's ebb and flow. No waste, no excess – just the right amount of support keeping your customers happy and your costs down.
Access to Expertise Without the Price Tag
Think about this – you get access to a team of well-trained, experienced customer support experts without spending a dime on training or recruitment. That’s the beauty of outsourcing customer service. You don’t have to compromise on quality to save costs. Your customers get top-notch support from seasoned professionals, ensuring their issues are resolved efficiently, enhancing their satisfaction and loyalty to your brand.
Focus Your Resources Where They Matter
Free up your internal resources by outsourcing the customer service load. It allows your team to concentrate on what they do best, whether it’s product development, marketing, or strategy. You get to channel your energy and finances into growth and innovation, driving your business forward without the distraction and cost of managing an in-house customer support team. It’s not just cost-effective; it’s a strategic move that positions your business for success.
Adaptability Without the Extra Cost
The flexibility that outsourcing customer service offers is unmatched. Need to scale up support during peak seasons? No problem. Want to scale down during slower periods? You got it. All these without the financial and logistical nightmares of hiring or letting go of staff. It’s seamless, it’s smooth, and yes, it’s cost-effective, keeping you agile and responsive to market demands without breaking the bank.
Seamless Integration Ensures Quality
When outsourcing customer service, pick a partner that seamlessly blends with your brand voice and values. It’s like finding a puzzle piece that fits perfectly, ensuring that your customers continue to receive the stellar service they are accustomed to. This union should be so smooth that your customers can’t tell the difference. They get the same warm, efficient, and reliable support as always, keeping satisfaction levels soaring high.
Training: The Quality Guarantee
Think outsourcing means a dip in service quality? Think again! The right outsourcing partner places immense emphasis on comprehensive training. The customer support representatives become an extension of your brand, equipped with ample knowledge about your products, services, and policies. Consistent quality training ensures your customer queries and issues are handled with expertise, efficiency, and empathy, maintaining the high standards you value.
Technology: Upping the Game
Embrace the technological edge that comes with outsourcing customer service. The cutting-edge tools and platforms employed by outsourcing partners amplify the quality of customer support. Advanced CRM systems, efficient ticketing platforms, and robust communication tools ensure every customer interaction is smooth, efficient, and effective. Quality customer support is now turbocharged with technology, ensuring your customers experience nothing but the best.
Global Reach with Local Touch
Worried about losing that personal touch while outsourcing customer service? Worry no more! The best outsourcing partners offer multilingual support, ensuring your global customer base feels right at home. Every interaction is personalized, culturally sensitive, and in the language your customers prefer. High-quality customer service, with a local touch, is now a global affair, delighting your diverse customer base and building stronger connections.
Customized Solutions, Consistent Quality
No two businesses are the same, and your unique needs deserve special attention. Customized customer service solutions ensure that your specific requirements are met without a hitch. Whether it's 24/7 support, multichannel communication, or specialized technical support, get exactly what you need, ensuring consistent quality and satisfaction across the board. Tailor-made solutions mean your customers always receive the attention, care, and excellence they deserve.
Performance Metrics and Regular Feedback
Ensure the outsourcing partner has a robust system for performance metrics and regular feedback. This transparency allows you to monitor, evaluate, and ensure the quality of customer service remains top-notch. Regular assessments and feedback loops enhance performance, iron out kinks, and keep the service standards sky-high, ensuring your customers always have delightful and satisfying interactions.
Navigate Budget Constraints
Hey there, budget navigator! Outsourcing customer service allows you to free up resources while ensuring your customers are in expert hands. No need to juggle finances for an in-house team, infrastructure, and training. Instead, enjoy the expertise of a dedicated team without the hefty price tag. Affordable excellence is not just a dream, it's your new reality!
Outsource without Outsourcing Quality
Concerned about compromising on quality while cutting costs? With outsourcing customer service, that’s a myth busted! The right partners guarantee trained professionals who understand the nuances of the Fintech world. Your customers enjoy seamless, knowledgeable, and prompt service, keeping their satisfaction and your reputation soaring high, all while staying within budget.
Access to Latest Technology
Don’t let budget constraints keep you from the technological advancements in customer service. Outsourcing grants you access to the latest tools and platforms that ensure efficient and effective support. Cutting-edge CRM systems, efficient ticketing platforms, and other robust tools amplify the quality of each customer interaction. You can enjoy technological excellence without breaking the bank.
Expertise at Every Turn
Imagine having a team of experts at your beck and call, without the financial strain. Outsourcing customer service in the Fintech industry brings you experienced professionals adept at handling diverse customer queries and concerns. They speak the language of Fintech, ensuring every interaction adds value to your customers and enhances their experience. You can relax, knowing your customers are in capable, expert hands.
Flexibility and Scalability on a Budget
Outsourcing customer service offers you the flexibility and scalability that a fixed in-house team might not. You can easily adjust the team size based on your current needs and budget without any long-term commitments or hefty investments. Your budget stays intact, your service stays top-notch, and you stay stress-free.
Global Support, Local Budget
Expand your global reach without expanding your expenses. Outsourcing customer service allows you to offer multilingual support to your diverse customer base, ensuring cultural sensitivity and personalized interactions. Deliver global excellence without the global expenditure, and watch your customer satisfaction and loyalty grow.
Efficient Problem Resolution
Quick, efficient problem resolution is key in the Fintech industry. Outsourced teams are trained for precisely this, ensuring your customers’ issues are resolved promptly and proficiently. Happy customers and a happy budget? Yes, it’s possible!
Hitting the High Notes of Cost-Efficiency
Meet Fintech Startup A, a small team with big dreams, tight on budget and rich in passion. By outsourcing customer service, they channeled funds to innovate and grow. They not only saved costs but ensured their customers were greeted with stellar service, creating a symphony of satisfaction and savings.
Uncompromised Quality and Innovation
Enter Fintech Company B, a growing entity facing the challenge of maintaining top-quality service amid rapid expansion. Their solution? Outsourcing customer service. The results were astonishing. They enjoyed access to trained experts, leading to enhanced customer satisfaction and loyalty, all while staying within budget and focusing on innovation.
Technology Triumphs
Here's Fintech Giant C, looking to integrate the latest technology into their customer service without shooting their budget sky-high. Outsourcing offered access to cutting-edge tools and platforms that ensured their customers experienced efficient and effective support, affirming their position as a tech-savvy leader in the industry.
Global Outreach on a Shoestring
Next up, Fintech Firm D, dreaming of global expansion but shackled by budget constraints. Outsourcing customer service turned the tides, offering multilingual support and cultural sensitivity, ensuring their global customers felt seen, heard, and understood. They expanded their reach without stretching their budget, hitting the sweet spot of global support and local expenditure.
Expert Hands, Light Pockets
Picture this: Fintech Company E, aiming for expertise in handling diverse customer queries and concerns. Outsourcing put them in touch with industry experts adept at speaking the language of Fintech, ensuring enriched customer interactions and enhanced satisfaction, all without the financial burden of an in-house team.
Solutions that Sing
Now, visualize Fintech Enterprise F, focused on quick, efficient problem resolution. Outsourced teams, trained specifically for the Fintech industry, ensured their customers' issues were resolved promptly and professionally, leaving a trail of happy customers and a healthy budget.
Outsourcing customer service: Flexible, Scalable, and Affordable
Lastly, Fintech Business G, needing to scale without financial strain. Outsourcing customer service allowed them the flexibility to adjust their team size as per their evolving needs, without any long-term commitments or significant investments, proving that scalability and affordability can indeed go hand in hand.
Conclusion
In the cost-and-quality ballet of the Fintech world, these companies danced their way to success by outsourcing customer service, creating harmonious stories of satisfied customers, innovative growth, and balanced budgets. Step into the world of successful outsourcing stories and let your Fintech company script its tale of triumph!

The Difference Between Customer Support And Customer Success Teams
When we talk about your business product or service, there is no doubt that both support and success teams are considered as essential assets for the entire customer lifecycle. Since customer support and customer success are often intertwined, we think that is critical to define and understand their differences and roles, especially when your company’s output is based on a certain tech infrastructure.
Customer support – A necessary way to be there for your customers.
Dedicated support teams pursue to ensure customer satisfaction through ongoing technical support for a certain product or service. These kinds of teams solve customer’s challenges, questions and concerns regarding individual issues and provide technical guidance. For a better understanding, we should define a couple of specific traits.
Removes obstacles
Regardless of the customer support channel – email, chat or call – the team in charge solves their problems as soon as customers submit a ticket or send an email, not before. Thus, the role of customer support is to meet their needs in a reactive manner, meaning that whenever an issue emerges they take care of it. In this way, a support team removes any kind of obstacles when it emerges in customer’s direct interaction path by providing necessary resources such as documentation or self-service portals.
Focuses on cost
The number of favorable customer experiences is inversely proportional to financial losses. In other words, based on Nicereply point of view, if a support team provide efficient solutions for customer’s problems, the churn rate, which means here the annual percentage at which customers stop subscribing to a service, will be reduced. However, support teams aren’t strictly a centered-cost department, as originally built, they can also impact revenue by advising on common reasons for churn or identify upsell and cross self-opportunities in their conversations with your business customers.
Has short-term objectives
According to Hubspot, support interactions are transactional which means when a customer submits a certain issue or question, those are solved by a support assistant – and may have in view immediate technical or usage issues. After all, the main purpose of support teams is to solve specific issues as quickly as possible in order to drive customer satisfaction, which is the main baseline for success teams.
Customer success – The next step in scaling customer experience.
From Gainsight perspective, customer success manages company-customer interactions and aligns client and vendor goals for mutually beneficial outcomes. Success teams influence revenue through their proactive actions in order to accomplish long-term objectives, but we will talk about all of these attributes below:
Uses proactive strategies
The main objective of a success team consists in initiating conversations with your customers before they contact you. Therefore, they have to be proactive, meet their needs, anticipate them and identify opportunities to solve problems that they are not yet confronted with, but they might be. Identifying these solutions in advance must be based on the company’s long-term objectives. Their job is to make sure that customers understand the full potential and value they can achieve from your product/service. In other words, success teams ensure insights-access for users regarding the most efficient way to use your solution and adopt it on a long-term.
Focuses on revenue
In this context, when we talk about scaling your business, customer success teams play their main role. They focus less on technical issues and more on the aspects that are directly related to business development. So they drive expansion via churn-reduction as in decreasing the number of unsubscribed customers and up-selling, cross-selling, referrals techniques in order to promote your business solutions.
Customer Success provides a whole mechanism not only for uncovering upsell and cross-sell opportunities but also for gaining advantage from them. Besides that, it’s the most desirable way to initiate reduction, helping subscription growth for a certain product or service.
Has long-term objectives
Success team’s interactions don’t have an end-point. As we mentioned earlier, they look at the entire customer’s process lifecycle in order to solve universal adoption issues and other common narrows that prevent users from achieving their goals. Moreover, as Gainsight believes, ensuring customer success brings about a significant positive impact on businesses as they focused on increasing retention, repeated purchases or lifetime value.
Different roles, same team
To conclude, support and success teams provide services for customers and help them generate value for your company. Both of them focus on successfully integrate the product or service in your users’ lifecycle with each aid, improving retention, boosting value, and increasing advocacy. The best businesses succeed in bringing support and success together, leveraging their differences to consolidate this entire process of removing obstacles that prevent your business customers from achieving their goals.
GlusterFS - Replicate a volume over two nodes
When you are using a load balancer with two or more backend nodes(web servers) you will probably need some data to be mirrored between the two nodes. A high availability solution is offered by GlusterFS.
Within this article, I am going to show how you can set volume replication between two CentOS 7 servers.
Let's assume this:
- node1.domain.com - 172.31.0.201
- node2.domain.com - 172.31.0.202
First, we edit /etc/hosts of each of the servers and append this:
172.31.0.201 node1.domain.com node1 172.31.0.202 node2.domain.com node2
We should now be able to ping between the nodes.
PING node2.domain.com (172.31.0.202) 56(84) bytes of data. 64 bytes from node2.domain.com (172.31.0.202): icmp_seq=1 ttl=64 time=0.482 ms 64 bytes from node2.domain.com (172.31.0.202): icmp_seq=2 ttl=64 time=0.261 ms 64 bytes from node2.domain.com (172.31.0.202): icmp_seq=3 ttl=64 time=0.395 ms --- node2.domain.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2001ms rtt min/avg/max/mdev = 0.261/0.379/0.482/0.092 ms
Installation:
Run these on both nodes:
yum -y install epel-release yum-priorities
Add priority=10 to the [epel]section in /etc/yum.repos.d/epel.repo
[epel] name=Extra Packages for Enterprise Linux 7 - $basearch #baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch failovermethod=priority enabled=1 priority=10 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
Update packages and install:
yum -y update yum -y install centos-release-gluster yum -y install glusterfs-server
Start glusterd service, also enable it to start at boot:
service glusterd start systemctl enable glusterd
You can use service glusterd status and glusterfsd --version to check all is working properly.
Remember, all the installation steps should be executed on both servers!
Setup:
On node1 server run:
[root@node1 ~]# gluster peer probe node2 peer probe: success. [root@node1 ~]# gluster peer status Number of Peers: 1 Hostname: node2 Uuid: 42ee3ddb-e3e3-4f3d-a3b6-5c809e589b76 State: Peer in Cluster (Connected)
On node2 server run:
[root@node2 ~]# gluster peer probe node1 peer probe: success. [root@node2 ~]# gluster peer status Number of Peers: 1 Hostname: node1.domain.com Uuid: 68209420-3f9f-4c1a-8ce6-811070616dd4 State: Peer in Cluster (Connected) Other names: node1 [root@node2 ~]# gluster peer status Number of Peers: 1 Hostname: node1.domain.com Uuid: 68209420-3f9f-4c1a-8ce6-811070616dd4 State: Peer in Cluster (Connected) Other names: node1
We need to create now the shared volume, and this can be done from any of the two servers.
[root@node1 ~]# gluster volume create shareddata replica 2 transport tcp node1:/shared-folder node2:/shared-folder force volume create: shareddata: success: please start the volume to access data [root@node1 ~]# gluster volume start shareddata volume start: shareddata: success [root@node1 ~]# gluster volume info Volume Name: shareddata Type: Replicate Volume ID: 30a97b23-3f8d-44d6-88db-09c61f00cd90 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: node1:/shared-folder Brick2: node2:/shared-folder Options Reconfigured: transport.address-family: inet nfs.disable: on
This creates a shared volume named shareddata, with two replicas on node1 and node2 servers, under /shared-folder path. It will also silently create the shared-folder directory if it doesn't exist.If there are more servers in the cluster, do adjust the replica number in the above command. The "force" parameter was needed, because we replicated in the root partition. It is not needed when creating under another partition.
Mount:
In order for the replication to work, mounting the volume is needed. Create a mount point:
mkdir /mnt/glusterfs
On node1 run:
[root@node1 ~]# echo "node1:/shareddata /mnt/glusterfs/ glusterfs defaults,_netdev 0 0" >> /etc/fstab [root@node1 ~]# mount -a [root@node1 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/VolGroup00-LogVol00 38G 1.1G 37G 3% / devtmpfs 236M 0 236M 0% /dev tmpfs 245M 0 245M 0% /dev/shm tmpfs 245M 4.4M 240M 2% /run tmpfs 245M 0 245M 0% /sys/fs/cgroup /dev/sda2 1014M 88M 927M 9% /boot tmpfs 49M 0 49M 0% /run/user/1000 node1:/shareddata 38G 1.1G 37G 3% /mnt/glusterfs
On node2 run:
[root@node2 ~]# echo "node2:/shareddata /mnt/glusterfs/ glusterfs defaults,_netdev 0 0" >> /etc/fstab [root@node2 ~]# mount -a [root@node2 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/VolGroup00-LogVol00 38G 1.1G 37G 3% / devtmpfs 236M 0 236M 0% /dev tmpfs 245M 0 245M 0% /dev/shm tmpfs 245M 4.4M 240M 2% /run tmpfs 245M 0 245M 0% /sys/fs/cgroup /dev/sda2 1014M 88M 927M 9% /boot tmpfs 49M 0 49M 0% /run/user/1000 node2:/shareddata 38G 1.1G 37G 3% /mnt/glusterfs
Testing:
On node1:
touch /mnt/glusterfs/file01 touch /mnt/glusterfs/file02
on node2:
[root@node2 ~]# ls /mnt/glusterfs/ -l total 0 -rw-r--r--. 1 root root 0 Sep 24 19:35 file01 -rw-r--r--. 1 root root 0 Sep 24 19:35 file02
This is how you mirror one folder between two servers. Just keep in mind, you will need to use the mount point /mnt/glusterfs in your projects, for the replication to work.
How To Install A .pxf Windows SSL Certificate On Your Linux Web Server
Windows uses .pfx for a PKCS #12 file. PFX stands for Personal eXhange Format. This is like a bag containing multiple cryptographic information. It can store private keys, certificate chains, certificates and root authority certificates. It is password protected to preserve the integrity of the contained data.
In order to install it on our apache/nginx web server we need to convert it PEM.
How To Install A .pxf Windows SSL Certificate On Your Linux Web Server
Upload first the .pfx to your linux server. You will need OpenSSL installed.
On Centos run:
yum install openssl
On Ubuntu run:
sudo apt-get update sudo apt-get install openssl
To decript the .pfx use:
openssl pkcs12 -in cert.pfx -out cert.pem
You will be prompted for the password that was used to encrypt the certificate. After providing it, you will need to enter a new password that will encrypt the private key.
The .pem file resulted will contain the encrypted public key, the certificate and some other information we will not use.Copy the key from inside and paste it to a new .key file.
Also copy the certificate from the .pem and put it in a new .cert file.
Remember to copy the whole blocks, including the dashed lines.
The private key file is still encrypted, so we have to decrypt it with:
openssl rsa -in cert.key -out cert.key
You will now be prompted for the password you set to encrypt the key. This will decrypt the private key file to itself.
To install the certificate to Nginx, you will need to import your .key and .cert in Nginx configuration file like this:
ssl_certificate /path/to/your/cert.pem; ssl_certificate_key /path/to/your/cert.key;
For Apache use:
SSLCertificateFile /path/to/your/cert.pem; SSLCertificateKeyFile /path/to/your/cert.key;
Mysqldump Through a HTTP Request with Golang
So, in a previous post I explained how one can backup all databases on a server, each in its own dump file. Let's take it to the next level and make a Golang program that will let us run the dump process with a HTTP request.
Assuming you already have Go installed on the backup server, create first a project directory in your home folder for example. Copy the mysql dump script from here and save it as dump.sh in your project folder. Modify ROOTDIR="/backup/mysql/" inside dump.sh to reflect current project directory.
Mysqldump
We will create a Golang script with two functions. One will launch the backup script when a specific HTTP request is done. The other one will put the HTTP call behind a authentication, so only people with credentials will be able to make the backup request.
package main
import (
"encoding/base64"
"fmt"
"log"
"net/http"
"os"
"os/exec"
"strings"
)
var username = os.Getenv("DB_BACKUP_USER")
var password = os.Getenv("DB_BACKUP_PASSWORD")
func BasicAuth(w http.ResponseWriter, r *http.Request, user, pass string) bool {
s := strings.SplitN(r.Header.Get("Authorization"), " ", 2)
if len(s) != 2 {
return false
}
b, err := base64.StdEncoding.DecodeString(s[1])
if err != nil {
return false
}
pair := strings.SplitN(string(b), ":", 2)
if len(pair) != 2 {
return false
}
return pair[0] == string(user) && pair[1] == string(pass)
}
func handler(w http.ResponseWriter, r *http.Request) {
if BasicAuth(w, r, username, password) {
cmd := exec.Command("bash", "dump.sh")
stdout, err := cmd.Output()
if err != nil {
log.Fatal(err)
}
fmt.Fprintf(w, string(stdout))
return
}
w.Header().Set("WWW-Authenticate", `Basic realm="Protected Page!!! "`)
w.WriteHeader(401)
w.Write([]byte("401 Unauthorized\n"))
}
func main() {
http.HandleFunc("/backup", handler)
http.ListenAndServe(":8080", nil)
}
This uses DB_BACKUP_USER and DB_BACKUP_PASSWORD that you will have to set as environment variables. Just append this to your ~/.bashrc file
export DB_BACKUP_USER="hello" export DB_BACKUP_PASSWORD="password"
Now run source ~/.bashrc to load them.
Build the executable with go build http-db-backup.go where http-db-backup.go is the name of your Go file. Now you need to run the executable with sudo, but while preserving the environment: sudo -E ./http-db-backup
Now if you open your browser and open http://111.222.333.444:8080/backup (where 111.222.333.444 is your backup machine IP) the backup process will start, and you will get the output of the dump.sh in your browser when backup finishes.
We can furthermore add another function to list the directory in browser, so you can download the needed backup or backups.
func lister(w http.ResponseWriter, r *http.Request) {
if BasicAuth(w, r, username, password) {
http.FileServer(http.Dir(".")).ServeHTTP(w, r)
return
}
w.Header().Set("WWW-Authenticate", `Basic realm="Protected Page!!! "`)
w.WriteHeader(401)
w.Write([]byte("401 Unauthorized\n"))
}All you need to do is to add http.HandleFunc("/", lister) to your main() and navigate to http://111.222.333.444:8080/ . You will be able to navigate the backup directory to download the dump files.
Introduction to iBeacons on iOS
Hello, I got my hands on some interesting devices from Estimote called iBeacons which they are used for sending signals to the users (iOS/ Android) phone using Bluetooth.
What I’m going to do next is to build an iOS app using these devices which changes the background color accordingly to the nearest one of these 3 beacons.
![]()
Introduction to iBeacons on iOS
The first thing that you have to do after you create a new project from XCode of Single View Application type is to install ‘EstimoteSDK’ using Cocoa pods. If you don’t have Cocoapods installed on your Mac please do it by following the instructions they offer.
From the terminal window use "cd" to navigate into your project directory and run "pod init". This will create a podfile in your project directory. Open it and under "# Pods for your project name" add the following line:
pod 'EstimoteSDK'
Then run "pod install" command in your terminal. After the installation of the cocoapod close the project and open the .workspace file and create a bridging header. Import there the EstimoteSDK with the code below.
#import <EstimoteSDK/EstimoteSDK.h>
Now let’s continue by creating a ‘iBeaconViewController’ with a UILabel inside of it having full width and height and the text aligned center, after this please create an IBOutlet to it and name it 'label' . Then set the new created view controller as the root view for the window.
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool {
// Override point for customization after application launch.
window?.rootViewController = UIBeaconViewController(nibName: String(describing: UIBeaconViewController.self), bundle: nil)
return true
}The next step is creating the ‘BeaconManager’< file, you have it’s content below.
import UIKit
enum MyBeacon: String {
case pink = "4045"
case magenta = "20372"
case yellow = "22270"
}
let BeaconsUUID: String = "B9407F30-F5F8-466E-AFF9-25556B57FE6D"
let RegionIdentifier: String = "IntelligentBee Office"
let BeaconsMajorID: UInt16 = 11111
class BeaconManager: ESTBeaconManager {
static let main : BeaconManager = BeaconManager()
}
But let’s first explain what is the purpose of each item in this file. So an iBeacon contains the following main properties, an UUID, MajorID, MinorID. All of these properties represents a way for the phone to know which device should listen to.
The MajorID is used when having groups of beacons and the MinorID is to know each specific device, the minor ids are represented in the MyBeacon enum among with the beacon color. The RegionIdentifier represents a way for the app to know what region are the beacons part of and it’s used to differentiate all the regions that are monitored by the app.
Now let’s go back on the UIBeaconViewController and start writing some action.
import UIKit
class UIBeaconViewController: UIViewController, ESTBeaconManagerDelegate {
// MARK: - Props
let region = CLBeaconRegion(
proximityUUID: UUID(uuidString: BeaconsUUID)!,
major: BeaconsMajorID, identifier: RegionIdentifier)
let colors: [MyBeacon : UIColor] =
[MyBeacon.pink: UIColor(red: 240/255.0, green: 183/255.0, blue: 183/255.0, alpha: 1),
MyBeacon.magenta : UIColor(red: 149/255.0, green: 70/255.0, blue: 91/255.0, alpha: 1),
MyBeacon.yellow : UIColor(red: 251/255.0, green: 254/255.0, blue: 53/255.0, alpha: 1)]
// MARK: - IBOutlets
@IBOutlet weak var label: UILabel!You can guess what region does, it defines a location to detect beacons, pretty intuitive. The colors is an array which contains the mapping between the minorID and the color of each beacon.
// MARK: - UI Utilities
func resetBackgroundColor() {
self.view.backgroundColor = UIColor.green
}
// MARK: - ESTBeaconManagerDelegate - Utilities
func setupBeaconManager() {
BeaconManager.main.delegate = self
if (BeaconManager.main.isAuthorizedForMonitoring() && BeaconManager.main.isAuthorizedForRanging()) == false {
BeaconManager.main.requestAlwaysAuthorization()
}
}
func startMonitoring() {
BeaconManager.main.startMonitoring(for: region)
BeaconManager.main.startRangingBeacons(in: region)
}
The functions above are pretty self describing from their names, one thing I need to describe is Monitoring and Ranging. The monitoring actions are triggered when the phone enters/ exits a beacons area and the ranging is based on the proximity of the beacon.
// MARK: - ESTBeaconManagerDelegate
func beaconManager(_ manager: Any, didChange status: CLAuthorizationStatus) {
if status == .authorizedAlways ||
status == .authorizedWhenInUse {
startMonitoring()
}
}
func beaconManager(_ manager: Any, monitoringDidFailFor region: CLBeaconRegion?, withError error: Error) {
label.text = "FAIL " + (region?.proximityUUID.uuidString)!
}
func beaconManager(_ manager: Any, didEnter region: CLBeaconRegion) {
label.text = "Hello beacons from \(region.identifier)"
}
func beaconManager(_ manager: Any, didExitRegion region: CLBeaconRegion) {
label.text = "Bye bye beacons from \(region.identifier)"
}
func beaconManager(_ manager: Any, didRangeBeacons beacons: [CLBeacon], in region: CLBeaconRegion) {
let knownBeacons = beacons.filter { (beacon) -> Bool in
return beacon.proximity != CLProximity.unknown
}
if let firstBeacon = knownBeacons.first,
let myBeacon = MyBeacon(rawValue:firstBeacon.minor.stringValue) {
let beaconColor = colors[myBeacon]
self.view.backgroundColor = beaconColor
}
else {
resetBackgroundColor()
}
}
func beaconManager(_ manager: Any, didFailWithError error: Error) {
label.text = "DID FAIL WITH ERROR" + error.localizedDescription
}
}
After the insertion of all the code, the app should run with no errors or warning and should look like this:


I hope this is a good introduction for iBeacons in iOS Mobile App Development. If you have any improvements or suggestions please leave a comment below.
You can get the code from here: https://github.com/intelligentbee/iBeaconTest
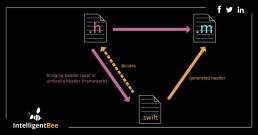
How to create a bridging header in iOS
Hello ! If you want to import a Objective-C code into a Swift Xcode project you definitely have to create a bridging header (this allows you to communicate with your old Objective-C classes from your Swift classes).
The process of doing this is very easy. Go to File -> New -> File… , a window will appear in which you will select “Objective-C File” , name the file however you choose, then select Create. A pop-up will appear asking you if you want to create a bridging header like in the image bellow.
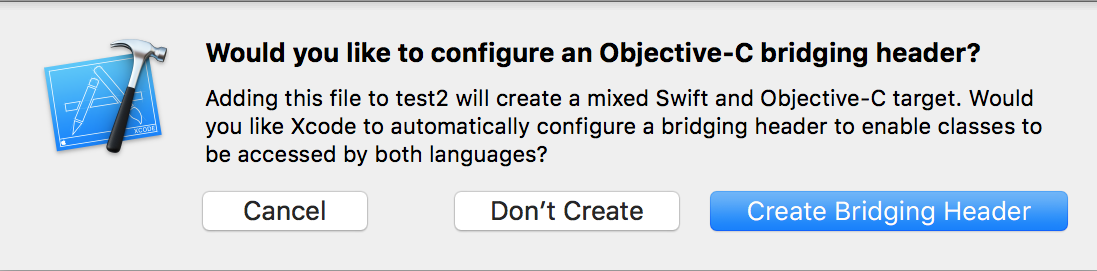
Choose “Create Bridging Header” and voila, you a have it.
To complete the process delete the .m file that you choose the name and move the bridging header to a more suitable group inside the project navigator.
That’s it, hope you find this post useful and if you have suggestions please leave a comment below.
Mysqldump Command - Useful Usage Examples
One of the tasks a sysadmin will always have on their list is backing up databases. These backups are also called dump files because, usually, they are generated with mysqldump command.
I am going to share a few tricks on mysqldump that will help when handling servers with many relatively small databases.
Mysqldump Command
The most simple way to backup databases would be using mysqldump command with the the --all-databases attribute. But I find that having each database saved in its own file more convenient to use.
Lets first suppose that you need to run a script that alters in databases, and that you just need a simple way to have a rollback point, just in case. I used to run something like this before:
for i in \ `ls /var/lib/mysql/`; \ do mysqldump -u root -p*** --skip-lock-tables --skip-add-locks --quick --single-transaction $i > $i.sql; done
where *** is your root password. The aditional parameters --skip-lock-tables --skip-add-locks --quick --single-transaction assure availability and consistency of dump file for InnoDB databases (the default storage engine as of MySQL 5.5.5).
Mysql stores databases in folders using same name as database name in /var/lib/mysql. The command picks database names from the listing of /var/lib/mysql folder and exports to files using same name adding the .sql.
There are 2 issues with the above command:
- It will try to execute a dump for every file/folder listed in
/var/lib/mysql. So if you have error logs or whatever other files it will create.sqldumps for them too. This will send just directory names as database names to export:for i in \ `find /var/lib/mysql/ -type d | sed 's/\/var\/lib\/mysql\///g'`;\ do mysqldump -u root -p*** --skip-lock-tables --skip-add-locks --quick --single-transaction $i > $i.sql; done
I find this to be hard to type and prefer to use one I will explain in point 2, since it also covers this.
- When database names have characters like
-the folder name will have@002instead. If that is the case, you can use something like:for i in \ `mysql -u root -p*** -e 'show databases'`;\ do mysqldump -u root -p*** --skip-lock-tables --skip-add-locks --quick --single-transaction $i > $i.sql;done
This picks database names to export form mysql
show databasescommand.
But, one time I had to export databases with / in their names. And there is no way to export as I showed above, since / can't be used in file names since it is actually a markup for directories. So I did this:
for i in \ `mysql -u root -p*** -e 'show databases'`;\ do mysqldump -u root -p*** --skip-lock-tables --skip-add-locks --quick --single-transaction $i > `echo $i | sed "s/\//_/g"`.sql;done
This wil replace / with _ for the dump file names.
For all of the above, we could (for obvious reasons) not use root mysql user. We could also run the backing up from a different location. In order to do this, we would need to create a mysql user with the right privileges on the machine we want to back up.
create user 'backupuser'@'111.222.333.444' identified by 'backuppassword'; grant select, show view, trigger, lock tables, reload, show databases on *.* to 'backupuser'@'111.222.333.444'; flush privileges;
where 111.222.333.444 is the ip of the remote machine.
Now you can issue mysqldump command from the other machine like this:
for i in \ `mysql -u backupuser -pbackuppassword -e 'show databases'`;\ do mysqldump -u backupuser -pbackuppassword -h 444.333.222.111 --skip-lock-tables --skip-add-locks --quick --single-transaction $i > `echo $i | sed "s/\//_/g"`.sql;done
where 444.333.222.111 is the ip of the machine we want to backup.
Lets take it to the next step , and put all our knowledge in a shell script.
#!/bin/bash
echo "Starting the backup script..."
ROOTDIR="/backup/mysql/"
YEAR=`date +%Y`
MONTH=`date +%m`
DAY=`date +%d`
HOUR=`date +%H`
SERVER="444.333.222.111"
BLACKLIST="information_schema performance_schema"
ADDITIONAL_MYSQLDUMP_PARAMS="--skip-lock-tables --skip-add-locks --quick --single-transaction"
MYSQL_USER="backupuser"
MYSQL_PASSWORD="backuppassword"
# Read MySQL password from stdin if empty
if [ -z "${MYSQL_PASSWORD}" ]; then
echo -n "Enter MySQL ${MYSQL_USER} password: "
read -s MYSQL_PASSWORD
echo
fi
# Check MySQL credentials
echo exit | mysql --user=${MYSQL_USER} --password=${MYSQL_PASSWORD} --host=${SERVER} -B 2>/dev/null
if [ "$?" -gt 0 ]; then
echo "MySQL ${MYSQL_USER} - wrong credentials"
exit 1
else
echo "MySQL ${MYSQL_USER} - was able to connect."
fi
#creating backup path
if [ ! -d "$ROOTDIR/$YEAR/$MONTH/$DAY/$HOUR" ]; then
mkdir -p "$ROOTDIR/$YEAR/$MONTH/$DAY/$HOUR"
chmod -R 700 $ROOTDIR
fi
echo "running mysqldump"
dblist=`mysql -u ${MYSQL_USER} -p${MYSQL_PASSWORD} -h $SERVER -e "show databases" | sed -n '2,$ p'`
for db in $dblist; do
echo "Backuping $db"
isBl=`echo $BLACKLIST |grep $db`
if [ $? == 1 ]; then
mysqldump ${ADDITIONAL_MYSQLDUMP_PARAMS} -u ${MYSQL_USER} -p${MYSQL_PASSWORD} -h $SERVER $db | gzip --best > "$ROOTDIR/$YEAR/$MONTH/$DAY/$HOUR/`echo $db | sed 's/\//_/g'`.sql.gz"
echo "Backup of $db ends with $? exit code"
else
echo "Database $db is blacklisted, skipped"
fi
done
echo
echo "dump completed"This will also compress the dump files to save storage.
Save the script as backup-mysql.sh somewhere on the machine you want backups saved, ensure you have the mysql user with the right credentials on the server hosting the mysql. You will also need mysql installed on the backup server. Executesudo chmod 700 backup-mysql.sh. Run the script with sudo sh backup-mysql.sh . After making sure it works properly, you can also add it to your crontab, so that it runs on a regular schedule.

Profiling web applications in Golang
I've been watching the 2017 Gophercon videos from here. There are many good talks that I would recommend watching from that list.
One that I really wanted to try out on my own was the profiling presentation that Peter Bourgon did. I assume for the sake of simplicity, he left some details out. I've been trying to figure them out on my own.
I was inspired to try to profile my own Golang web apps using the method he presented in his talk. So in this post I'll show you a simplified example of how to profile your own web applications in more detail.
The web app
To see a practical example of profiling and to keep it simple, we need to create a web app that when called on a particular route, performs some sort of calculation and returns a result in it's payload.
If we were to mimic real life scenarios, we would be here all day. So just to keep it simple, we will create a single route that calculates the 25th Fibonacci number when it's called and returns it in the response body.
I've written two versions of the Fibonacci function before hand, one that performs recursion (exponential time - very CPU intensive) and one that calculates the number using a vector (linear time - not very CPU intensive).
In order to use the profiling tool, you need to import the net/http/pprof package and register some routes. In the presentation I mentioned earlier, the speaker mentioned that we could leave this imported even in production environments since it does not affect performance.
package main
import (
"fmt"
"log"
"net/http"
"net/http/pprof"
)
// O(n) Fibonacci
func linearFibonacci(n int) int {
// Create an int array of size n + 1
v := make([]int, n+1)
// F(0) = 0
v[0] = 0
// F(1) = 1
v[1] = 1
// F(i) = F(i-1) + F(i-2)
for i := 2; i <= n; i++ {
v[i] = v[i-1] + v[i-2]
}
// F(n) - return the n-th Fibonacci number
return v[n]
}
// O(2^n) Fibonacci
func exponentialFibonacci(n int) int {
// F(0) = 0
if n == 0 {
return 0
}
// F(1) = 1
if n == 1 {
return 1
}
// F(n) = F(n-1) + F(n-2) - return the n-th Fibonacci number
return exponentialFibonacci(n-1) + exponentialFibonacci(n-2)
}
// HTTP request handler
func handler(w http.ResponseWriter, r *http.Request) {
// return the 25th Fibonacci number in the response payload
fmt.Fprintf(w, "%d", exponentialFibonacci(25))
}
func main() {
// Create a new HTTP multiplexer
mux := http.NewServeMux()
// Register our handler for the / route
mux.HandleFunc("/", handler)
// Add the pprof routes
mux.HandleFunc("/debug/pprof/", pprof.Index)
mux.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
mux.HandleFunc("/debug/pprof/profile", pprof.Profile)
mux.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
mux.HandleFunc("/debug/pprof/trace", pprof.Trace)
mux.Handle("/debug/pprof/block", pprof.Handler("block"))
mux.Handle("/debug/pprof/goroutine", pprof.Handler("goroutine"))
mux.Handle("/debug/pprof/heap", pprof.Handler("heap"))
mux.Handle("/debug/pprof/threadcreate", pprof.Handler("threadcreate"))
// Start listening on port 8080
if err := http.ListenAndServe(":8080", mux); err != nil {
log.Fatal(fmt.Sprintf("Error when starting or running http server: %v", err))
}
}As you can see, this is a really simple application, save it to a file called main.go and build it like this: go build -o myserver main.go .
Now you can run your binary: ./myserver and to check if it's working we'll send a request to it:
$ curl http://localhost:8080 75025
The CPU profile
Now, while the server is running, you will need to run two commands in parallel. You first need to start the profiling tool which will record data for 30 seconds after it is run AND as it is running, run the Apache Benchmark tool to send a few requests it's way.
So you will need to run the profiling tool like this:
go tool pprof -seconds 30 myserver http://localhost:8080/debug/pprof/profile
While that's running, run the benchmark:
ab -k -c 8 -n 100000 "http://127.0.0.1:8080/"
This will create a total of 100,000 keep-alive requests to your server, using 8 cores. To better understand what this benchmark command does, it is explained in the link provided.
After 30 seconds, the profiling tool will show a prompt for commands that will look something like this:
$ go tool pprof -seconds 30 myserver http://localhost:8080/debug/pprof/profile Fetching profile from http://localhost:8080/debug/pprof/profile?seconds=30 Please wait... (30s) Saved profile in /Users/username/pprof/pprof.myserver.localhost:8080.samples.cpu.013.pb.gz Entering interactive mode (type "help" for commands) (pprof)
Here you can run commands to show you how much of CPU time each function took and other useful information. For example, if I run top5 it will list the top 5 functions that are hogging the CPU:
(pprof) top5
84.57s of 85.18s total (99.28%)
Dropped 87 nodes (cum <= 0.43s)
Showing top 5 nodes out of 30 (cum >= 1.09s)
flat flat% sum% cum cum%
51.93s 60.97% 60.97% 51.93s 60.97% main.exponentialFibonacci
20.57s 24.15% 85.11% 20.59s 24.17% fmt.(*pp).doPrintf
12.06s 14.16% 99.27% 12.06s 14.16% syscall.Syscall
0.01s 0.012% 99.28% 11.22s 13.17% net.(*netFD).Write
0 0% 99.28% 1.09s 1.28% bufio.(*Reader).ReadLineAs you can see the exponentialFibonacci function really hogs the CPU.
Please note: These values might differ on your machine. For reference I'm using a MacBook Pro (Retina, 13-inch, Early 2015), 2.7 GHz Intel Core i5 Processor and 8 GB 1867 MHz DDR3 of Memory.
If we wanted to see a graph of this profile we need to run the web command like this:
(pprof) web (pprof)
This will open up your default browser and display an image of the profile. Here's a crop of the image that concerns our Fibonacci function:
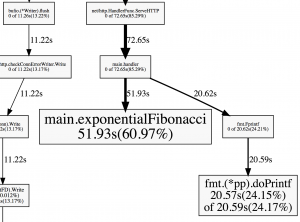
So during that profile, 60.97% of the time, the exponentialFibonacci was running on the CPU.
Optimizations
Now, we know from the theory that O(n) < O(2^n). Let's see if this holds up in practice, it we were to replace the exponentialFibonacci call with linearFibonacci inside the handler function.
Now we run the profile again. You can immediately see that it took less time because the benchmark actually finishes really fast this time.
If we run top5 now, the linearFibonacci function doesn't even make the cut. Even if you try to do top100 you will not find it because the compiler inlined that particular code.
So we need to rebuild the application with the compiler flags that disable inlining like this:
go build -gcflags -l -o myserver main.go
Now even with this flag enabled I had a hard time finding the function in the top. I went ahead and increased the hard-coded value for the n-th Fibonacci number to 10,000. So I'm looking for the 10,000th Fibonacci number, this number doesn't even fit inside the integer datatype in Golang. It will overflow several times before coming to a stop. I also increased the benchmark to 1,000,000 requests.
Now if I run top5 I get:
(pprof) top5
36.21s of 46.49s total (77.89%)
Dropped 226 nodes (cum <= 0.23s)
Showing top 5 nodes out of 102 (cum >= 1.97s)
flat flat% sum% cum cum%
25.94s 55.80% 55.80% 26.23s 56.42% syscall.Syscall
3.38s 7.27% 63.07% 3.38s 7.27% runtime.kevent
2.60s 5.59% 68.66% 2.60s 5.59% runtime.usleep
2.32s 4.99% 73.65% 4.26s 9.16% main.linearFibonacci
1.97s 4.24% 77.89% 1.97s 4.24% runtime.mach_semaphore_signalOr in graphical format:
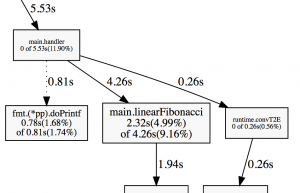
As you can see, it barely even makes a dent.
So for this test, calculating the 25th Fibonacci number recursively takes 60% of the CPU while calculating the 10,000th Fibonacci number linearly takes 4% of the CPU (without inlining).
Another useful command for pprof to see how much CPU time a function takes is the list command. Or, if you're like me, to find out if a function is actually called.
For our linearFibonacci function it looks like this:
(pprof) list linearFibonacci
Total: 46.49s
ROUTINE ======================== main.linearFibonacci in /Users/username/workspace/go/src/github.com/username/test_profiling/main.go
2.32s 4.26s (flat, cum) 9.16% of Total
. . 8:)
. . 9:
. . 10:// O(n) Fibonacci
. . 11:func linearFibonacci(n int) int {
. . 12: // Create an int array of size n + 1
10ms 1.95s 13: v := make([]int, n+1)
. . 14:
. . 15: // F(0) = 0
. . 16: v[0] = 0
. . 17: // F(1) = 1
. . 18: v[1] = 1
. . 19:
. . 20: // F(i) = F(i-1) + F(i-2)
260ms 260ms 21: for i := 2; i <= n; i++ {
2.05s 2.05s 22: v[i] = v[i-1] + v[i-2]
. . 23: }
. . 24:
. . 25: // F(n) - return the n-th Fibonacci number
. . 26: return v[n]
. . 27:}A better comparison
A better way to compare the two methods, and the theory to practice, is this:
- Knowing that the exponentialFibonacci method is O(2^n), it would take approximately 2^25 = 33554432 instructions to calculate the 25th Fibonacci number.
- Linearly, calculating the 33554432th Fibonacci number should take roughly the same time as calculating the 25th number exponentially.
So following the methodology above we do this:
- Build the application using the exponentialFibonacci(25) call.
- Start the application.
- Start the Apache Benchmark for 1,000,000 requests.
- Start the CPU profile for 30s seconds.
We get this:
(pprof) top5
98.27s of 99.02s total (99.24%)
Dropped 64 nodes (cum <= 0.50s)
Showing top 5 nodes out of 30 (cum >= 1.30s)
flat flat% sum% cum cum%
60.78s 61.38% 61.38% 60.78s 61.38% main.exponentialFibonacci
24.54s 24.78% 86.16% 24.54s 24.78% fmt.(*pp).doPrintf
12.95s 13.08% 99.24% 12.95s 13.08% syscall.Syscall
0 0% 99.24% 1.30s 1.31% bufio.(*Reader).ReadLine
0 0% 99.24% 1.30s 1.31% bufio.(*Reader).ReadSliceNow for the second part:
- Build the application using the linearFibonacci(33554432) call.
- Start the application.
- Start the Apache Benchmark for 1,000,000 requests.
- Start the CPU profile for 30s seconds.
We get this:
(pprof) top5
49280ms of 49870ms total (98.82%)
Dropped 92 nodes (cum <= 249.35ms)
Showing top 5 nodes out of 29 (cum >= 470ms)
flat flat% sum% cum cum%
28650ms 57.45% 57.45% 44400ms 89.03% main.linearFibonacci
15660ms 31.40% 88.85% 15660ms 31.40% runtime.memclr
3910ms 7.84% 96.69% 3910ms 7.84% runtime.usleep
590ms 1.18% 97.87% 590ms 1.18% runtime.duffcopy
470ms 0.94% 98.82% 470ms 0.94% runtime.mach_semaphore_timedwaitAs you can see, the flat percentages, which is how much of the time was spent in the routine itself, is roughly the same. 61.38% vs 57.45%, it's about 4% difference between them.
Profiling memory
Using the same process, you can run the following command to profile memory:
go tool pprof -alloc_objects myserver http://localhost:8080/debug/pprof/heap
If you run a top command you should see something like this:
(pprof) top10
9741685 of 9927382 total (98.13%)
Dropped 7 nodes (cum <= 49636)
Showing top 10 nodes out of 33 (cum >= 99079)
flat flat% sum% cum cum%
3182489 32.06% 32.06% 3182489 32.06% net/textproto.(*Reader).ReadMIMEHeader
2050835 20.66% 52.72% 2050835 20.66% context.WithCancel
1068043 10.76% 63.47% 8447075 85.09% net/http.(*conn).readRequest
675175 6.80% 70.28% 5155947 51.94% net/http.readRequest
667729 6.73% 77.00% 667729 6.73% net/url.parse
655370 6.60% 83.60% 1414760 14.25% main.handler
618866 6.23% 89.84% 618866 6.23% main.linearFibonacci
589833 5.94% 95.78% 589833 5.94% net/textproto.(*Reader).ReadLine
134266 1.35% 97.13% 172250 1.74% net/http.newBufioWriterSize
99079 1% 98.13% 99079 1% sync.(*Pool).pinSlowConclusion
Now that you've seen the basics on how to profile your Golang web apps, you can start diving into heavier stuff like this. Take some time and run a profile on your own Golang web apps.
Also, you should see the Gophercon talk I mentioned at the start of this post, it's quite good.